ShellScript
シェルスクリプトとしてのRuby
Rubyをシェルスクリプトとして使う方法を詳述します.数値計算ではすでにあるプログラムの入力パラメータを変えて,繰り返し計算で精度や時間を検証するという作業が頻発します.このようなときにいちいちコマンドを打ち込むのでなく,スクリプトを書いて自動的に実行させるということをプロのプログラマはやってます.このような場面でRubyはもっとも強力な言語です.
課題1
Piをモンテカルロ法で解くプログラムpi0.rbの試行回数を変えて実行するスクリプトは 以下の通り.
number=[10,100,1000]
number.each do |num1|
res=`echo #{num1} | ruby pi0.rb`
puts "#{num1} #{res}"
end
実際に実行し,結果を示せ.
Rubyの解説をすこし
- each
- 配列にある要素全てを順番に|num1|にいれて実行するループ.
- コマンド出力
- `コマンド`(バッククオートで囲まれています)で実行したいコマンドを実行することができます.上のスクリプトではその出力をresに入れています.#{num1}はnum1の中身が展開されて,つまり数値に変換されて入っています.
- |
- 縦棒はlinuxのパイプラインと呼ばれる機能です.echo出力をruby pi0.rbに渡します.
課題2
以下のスクリプトを参考にして試行回数の増加に伴う誤差の変化を示せ.
pi=Math::PI (pi-res).abs
課題3
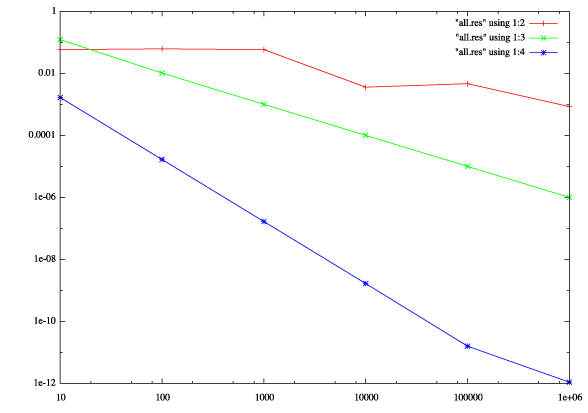
さらに,数値積分のプログラムを同時に実行するようにスクリプトを書き,下記のような出力を得よ.ここで第1列は試行あるいは分割数,2列がモンテカルロ法,3列が単純な矩形近似,4列が台形近似の結果である.
[BobsNewPBG4-6:~/NumRecipeEx07/Pi] bob% cat all.res
10 0.058407346410207 0.122661139820753 0.001666664682633
100 0.061592653589793 0.010217666616163 0.000016666666663
1000 0.058407346410207 0.001002167666673 0.000000166666673
10000 0.003592653589793 0.000100021667573 0.000000001666573
100000 0.004647346410207 0.000010000215923 0.000000000015923
1000000 0.000848653589793 0.000001000000903 0.000000000001097
課題4
上記のスクリプトの出力をloglog(両対数)で表示するためのgnuplotのコマンドです.
gnuplot> set logscale x gnuplot> set logscale y gnuplot> plot "res.all" using 1:2 with linespoints
3列,4列目も加えて以下のようなグラフを描け.
ちょっと高度なコントロール
より複雑なコントロールを示します.時間があれば解読してください.狙いは,
- あらかじめ定まった入力方法やファイルをどうやって書き換えるか.
- あらかじめ定まった出力形式(これは,人に優しくするため不用な文字があります)から,必要な情報をどうやってとり出して,成型するか
です.下準備であらかじめ定まった入出力を与えるプログラムを作ります.その後,Rubyによるファイル成型のアイデアを示します.
下準備
コイン投げを改良して,平均(Mean)と標準偏差(Root mean square:RMS)を計算するようにする.
number = gets.chomp.to_i
total = Array.new(number+1,0)
iter = gets.chomp.to_i
puts "Number:"+number.to_s
puts "Iter :"+iter.to_s
iter.times do
up=0
number.times do
up+=rand(2)
end
total[up]+=1
end
mean =0
sum2 =0
(number+1).times {|i|
mean+=i*total[i]
sum2+=i*i*total[i]
}
mean=mean.to_f/iter
puts "Mean:"+mean.to_s
disp=sum2.to_f/iter- mean*mean
puts "RMS :"+Math::sqrt(disp).to_s
これを実行すると
[BobsNewPBG4-6:~/NumRecipeEx07/Week5] bob% ruby coin2.rb 100 10000 Number:100 Iter :10000 Mean:50.0513 RMS :4.97870146825454
となる.入力をファイル(INPUT)から読み込み,ファイル(OUTPUT)へ出力するようにする.
[BobsNewPBG4-6:~/NumRecipeEx07/Week5] bob% cat INPUT 100 10000 [BobsNewPBG4-6:~/NumRecipeEx07/Week5] bob% ruby coin2.rb < INPUT > OUTPUT [BobsNewPBG4-6:~/NumRecipeEx07/Week5] bob% cat OUTPUT Number:100 Iter :10000 Mean:50.0102 RMS :4.94569468932326
INPUTファイルの編集
INPUT.origという以下のようなファイルを用意する.
[BobsNewPBG4-6:~/NumRecipeEx07/Week5] bob% cat INPUT.orig #NUMBER 10000
この#NUMBERをrubyで書き換えてINPUTファイルを生成する.
number=[10,100]
inData = File.read("INPUT.orig")
number.each do |num1|
infile = open("INPUT","w")
infile.puts inData.sub(/#NUMBER/,"#{num1}")
infile.close
puts `ruby coin2.rb < INPUT`
puts ' '
end
実行すると以下のようになる.
[BobsNewPBG4-6:~/NumRecipeEx07/Week5] bob% ruby CoinControl.rb Number:10 Iter :10000 Mean:5.0128 RMS :1.58468803238997 Number:100 Iter :10000 Mean:50.054 RMS :4.96766383725789
OUTPUTファイルからの値の抽出
OUTPUTファイルから正規表現を使ってNumber, RMSを含んだ行を取りだし, splitで分けて数値を抽出する.
number=[10,100,1e3]
inData = File.read("INPUT.orig")
number.each do |num1|
infile = open("INPUT","w")
infile.puts inData.sub(/#NUMBER/,"#{num1}")
infile.close
`ruby coin2.rb < INPUT >OUTPUT`
outData = File.read("OUTPUT")
m=outData.scan(/Number.*$/)[0]
num=m.split(/:/)[1].chomp
m=outData.scan(/RMS.*$/)[0]
rms=m.split(/:/)[1].chomp]
puts "#{num} #{rms}"
end
outDataにいれたOUTPUTの文字列から,Numberを含む行をscanし,その配列の中身を[0]で取りだし,splitで分けた2番目の要素を取り出しています.結果は以下の通り.
[BobsNewPBG4-6:~/NumRecipeEx07/Week5] bob% ruby CoinControl.rb 10 1.58974770010842 100 5.00486186722476 1000 15.7354073703219
抽出の仕方には他にもいくつかやり方がある.
grep
m=outData.grep(/Number/)[0] num=m.split(/:/)[1].chomp
scanするかわりにgrepで一行まるごと取り出しています.UNIXコマンドのgrepに近い使い方ができます.
grep
str1=`grep Number OUTPUT` num=str1.split(/:/)[1].chomp
同じことをUNIXコマンド`grep`で一行取り出しています.
ファイルを1行ごとに操作
outfile = open("OUTPUT","r")
while line = outfile.gets
if line =~ /Number/ then
num=line.split(/:/)[1].chomp
end
end
grep操作をrubyで置き換えて実行しています.
match
m=outData.match(/Number:/) num=m.post_match.to_a[0].chomp
ちょっと毛色を変えてmatchを使っています.matchでNumber:を取りだし,その後ろにある文字列(post_match)を行毎に区切って(to_a),その1番目を取り出しています.
Keyword(s):
References:[LinuxEx]