非線形最小2乗法(NonLinearFit)
非線形最小2乗法の原理
前章では,データに近似的にフィットする最小二乗法を紹介した.ここでは,フィット式が多項式のような線形関係にない関数の最小二乗法を紹介する.図のようなデータにフィットする場合を考えよう.
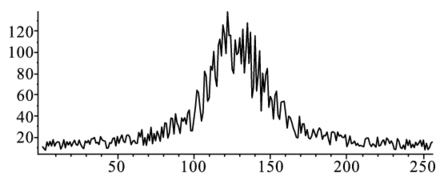 |
このデータにあてはめるのはローレンツ関数,
$$ F \left(x;\mathbf{a} \right)=a _{1}+ \frac{a _{2}}{a _{3}+\left(x -a _{4}\right)^{2}} $$である.この関数の特徴は,今まで見てきた関数と違いパラメータが線形関係になっていない.誤差関数は,いままでと同様に
$$ \chi ^{2}\left(\mathbf{a} \right)={\sum_i^N }d _{i }^{2}=\sum_i^N \left(F \left(x _{i };a \right)-y _{i }\right)^{2} $$で,$a={a_0, a_1,..}$をパラメータとして変えた時に最小となる値を求める点もかわらない.しかし,線形の最小二乗法のように微分しても一元の方程式にならず,連立方程式を単に解くだけでは求まらない.
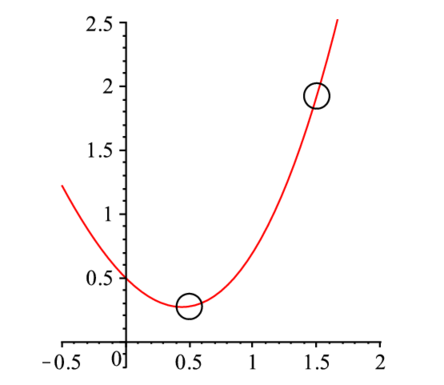
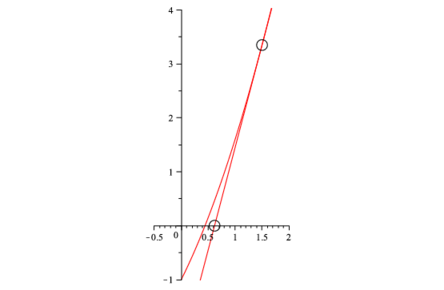
そこで図のような2次関数の最小値を求める場合を考える.最小値の点$a_0$のまわりで,Taylor展開すると,$\mathbf{d,D}$をそれぞれの係数とすると,
$$ \chi^2 \left( \mathbf{a} \right)= \chi^2 \left( \mathbf{a_0} \right) - \mathbf{d} \left(\mathbf{a}-\mathbf{a_0} \right) +\frac{1}{2} \mathbf{D} \left(\mathbf{a}-\mathbf{a_0} \right)^{2} $$である.最小の点$a_0$は,微分が$0$になるので,
$$ \mathbf{a _{0}}=\mathbf{a} + \mathbf{D} ^{-1} \times (-\mathbf{d}) $$と予測される.図を参照して上の式を導け.またその意味を考察せよ.
 |
 |
現実には高次項の影響で計算通りにはいかず,単に最小値の近似値を求めるだけである.これは,$ \chi \left(\mathbf{a} \right) ^{2}$の微分関数の解をNewton法で求める操作に対応する.つまり,この操作を何度も繰り返せばいずれ解がある精度で求まるはず.
具体的な手順
パラメータの初期値を
$$ a_{{0}}+\Delta\,a,\,b_{{0}}+\Delta\,b,\,c_{{0}}+\Delta\,c,\,d_{{0}}+\Delta\,d $$とする.このとき関数$f$を真値$a_0, b_0, c_0, d_0$のまわりでテイラー展開し,高次項を無視すると
$$ \Delta\,f=f \left( a_{{0}}+\Delta\,a_{{1}},b_{{0}}+\Delta\,b_{{1}},c_{{0}}+\Delta\,c_{{1}},d_{{0}}+\Delta\,d_{{1}} \right) -f \left( a_{{0}},b_{{0}},c_{{0}},d_{{0}} \right) $$ $$ =\left(\frac{\partial }{\partial a }f \right)_{0}\Delta a _{1}+\left(\frac{\partial }{\partial b }f \right)_{0}\Delta b _{1}+\left(\frac{\partial }{\partial c }f \right)_{0}\Delta c _{1}+\left(\frac{\partial }{\partial d }f \right)_{0}\Delta d _{1} $$となる.
課題でつくったデータはt = 1からt = 256までの時刻に対応したデータ点$f_{1},\,f_{2},\,\cdots f_{256}$とする.各測定値とモデル関数から予想される値との差$\Delta f_1,\Delta f_2,\cdots,\Delta f_{256}$は, $$ \left(\begin{array}{c}\Delta f _{1} \\\Delta f _{2} \\ \vdots \\\Delta f _{256} \\\end{array}\right)=J \left(\begin{array}{c}\Delta a _{1} \\\Delta b _{1} \\\Delta c _{1} \\\Delta d _{1} \\\end{array}\right) $$ となる.ここで$J$はヤコビ行列と呼ばれる行列で,4列256行 $$ J =\left(\begin{array}{cccc}\left(\frac{\partial }{\partial a }f \right)_{1} & \left(\frac{\partial }{\partial b }f \right)_{1} & \left(\frac{\partial }{\partial c }f \right)_{1} & \left(\frac{\partial }{\partial d }f \right)_{1} \\ \vdots & \vdots & \vdots & \vdots \\\left(\frac{\partial }{\partial a }f \right)_{256} & \left(\frac{\partial }{\partial b }f \right)_{256} & \left(\frac{\partial }{\partial c }f \right)_{256} & \left(\frac{\partial }{\partial d }f \right)_{256} \\\end{array}\right) $$ である.このような矩形行列の逆行列は転置行列$J^T$を用いて,` $$ J ^{-1}=\left(J ^{T }J \right)^{-1}J ^{T } $$ と表わされる.したがって,真値からのずれは $$ \left(\begin{array}{c}\Delta a_2 \\\Delta b_2 \\\Delta c_2 \\\Delta d_2 \\\end{array}\right) =\left(J ^{T }J \right)^{-1}J ^{T } \left(\begin{array}{c}\Delta f _{1} \\\Delta f _{2} \\ \vdots \\\Delta f _{256} \\\end{array}\right) $$ で求められる.理想的には$(\Delta a_2,\,\Delta b_2,\,\Delta c_2,\,\Delta d_2)$は$(\Delta a,\,\Delta b,\,\Delta c,\,\Delta d)$に一致するはずだが,測定誤差と高次項のために一致しない.初期値に比べ,より真値に近づくだけ.そこで,新たに得られたパラメータの組を新たな初期値に用いて,より良いパラメータに近付けていくという操作を繰り返す.新たに得られたパラメータと前のパラメータとの差がある誤差以下になったところで計算を打ち切り,フィッティングの終了となる.
Mapleによる解法の指針
線形代数計算のためにサブパッケージとしてLinearAlgebraを呼びだしておく.
> restart;
with(plots):
with(LinearAlgebra):データを読み込む.
> ndata:=8:
f1:=t->subs({a1=1,a2=10,a3=1,a4=4},a1+a2/(a3+(t-a4)^2) );データの表示
> T:=[seq(f1(i),i=1..ndata)]:
listplot(T);
l1:=listplot(T):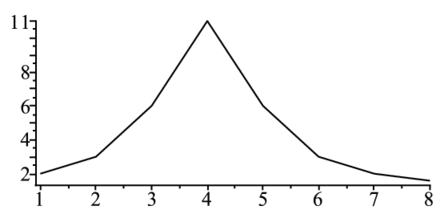 |
ローレンツ型の関数を仮定し,関数として定義.
> f:=t->a1+a2/(a3+(t-a4)^2); nparam:=4:ヤコビアンの中の微分を新たな関数として定義.
> for i from 1 to nparam do
dfda||i:=unapply(diff(f(x),a||i),x);
end do;ここで,"$||$"は連結作用素とよばれるMapleのコマンドで,$dfda||1 \mapsto dfda1$と連結する. 初期値を仮定して,データとともに関数を表示.
> g1:=Vector([1,8,1,4.5]):
guess1:={}:
for i from 1 to nparam do
guess1:={op(guess1),a||i=g1[i]};
end do:
guess1;> p1:=plot(subs(guess1,f(x)),x=1..ndata):
display(l1,p1); 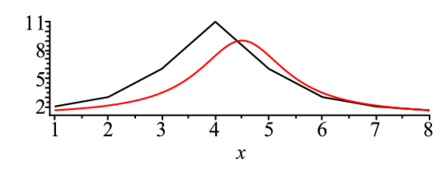 |
見やすいように,小数点以下を3桁表示に制限する.
> interface(displayprecision=3):
> df:=Vector([seq(subs(guess1,T[i]-f(i)),i=1..ndata)]);> Jac:=Matrix(ndata,nparam):
for i from 1 to ndata do
for j from 1 to nparam do
Jac[i,j]:=evalf(subs(guess1,dfda||j(i)));
end do:
end do:
Jac;> tJac:=(MatrixInverse(Transpose(Jac).Jac)).Transpose(Jac);> g2:=tJac.df;
g1:=g1+g2;これをまたもとの近似値(guess)に入れ直して表示させると以下のようになる.カーブがデータに近づいているのが確認できよう.この操作をずれが十分小さくなるまで繰 り返す.
> guess1:={seq(a||i=g1[i],i=1..nparam)};
p1:=plot(subs(guess1,f(x)),x=1..ndata):
display(l1,p1);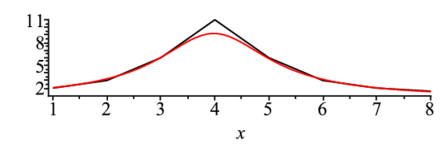 |
4回ほど繰り返すと以下の通り,いい値に収束している. $$ guess1:=\{a1 = 1.006, a2 = 9.926, a3 = .989, a4 = 4.000\} $$
Gauss-Newton法に関するメモ
このGauss-Newton法と呼ばれる非線形最小二乗法は線形問題から拡張した方法として論理的に簡明であり,広く使われている.しかし,収束性は高くなく,むしろ発散しやすいので注意が必要.2次の項を無視するのでなく,うまく見積もる方法を用いたのがLevenberg-Marquardt法である.明快な解説がNumerical Recipes in C(C 言語による数値計算のレシピ)WilliamH.Press 他著,技術評論社1993にある.
課題
- 一山ピークへのフィット
以下の256個のデータ
> ndata:=256; f1:=t->subs({a1=10,a2=40000,a3=380,a4=128},a1+a2/(a3+(t-a4)^2) );
> T:=[seq(f1(i)*(0.6+0.8*evalf(rand()/10^12)),i=1..ndata)]:
> f:=t->a1+a2/(a3+(t-a4)^2);で近似したときのパラメータa1,a2,a3,a4を求めよ.ただし,パラメータの初期値は,ある程度近い値にしないと収束しない.
- 二山ピークのフィット
以下のように作成したデータ
> ndata:=256; f1:=t->subs({a=10,b=40000,c=380,d=128},a+b/(c+(t-d)^2) );
> f2:=t->subs({a=10,b=40000,c=380,e=90},a+b/(c+(t-e)^2) );
> T:=[seq((f1(i)+f2(i))*(0.6+0.2*evalf(rand()/10^12)),i=1..ndata)]:を
> f:=t->a1+a2/(a3+(t-a4)^2)+a2/(a3+(t-a5)^2);で近似したときのパラメータを求めよ.
> l1:=listplot(T): display(l1);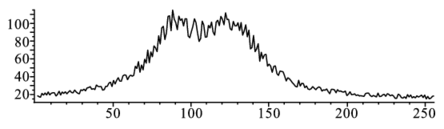 |
解答例
2. ふた山ピークへのフィット.
> restart; with(plots): with(LinearAlgebra):
> f1:=t->subs({a=10,b=40000,c=380,d=128},a+b/(c+(t-d)^2) );
> f2:=t->subs({a=10,b=40000,c=380,e=90},a+b/(c+(t-e)^2) );
> T:=[seq((f1(i)+f2(i))*(0.6+0.2*evalf(rand()/10^12)),i=1..256)]:> l1:=listplot(T):
> f:=t->a1+a2/(a3+(t-a4)^2)+a2/(a3+(t-a5)^2);
nparam:=5:> for i from 1 to nparam do
dfda||i:=unapply(diff(f(x),a||i),x);
end do;> g1:=Vector([10,1200,10,125,90]);> guess1:={seq(a||i=g1[i],i=1..nparam)};> p1:=plot(subs(guess1,f(x)),x=1..256):
display(l1);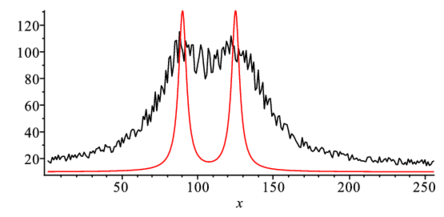 |
> df:=Vector([seq(subs(guess1,T[i]-f(i)),i=1..256)]):
Jac:=Matrix(1..256,1..nparam,sparse):
for i from 1 to 256 do
for j from 1 to nparam do
Jac[i,j]:=evalf(subs(guess1,dfda||j(i)));
end do:
end do:
tJac:=(MatrixInverse(Transpose(Jac).Jac)).Transpose(Jac):
g2:=tJac.df; g1:=g1+g2;> guess1:={seq(a||i=g1[i],i=1..nparam)};
p1:=plot(subs(guess1,f(x)),x=1..256):
display(l1,p1);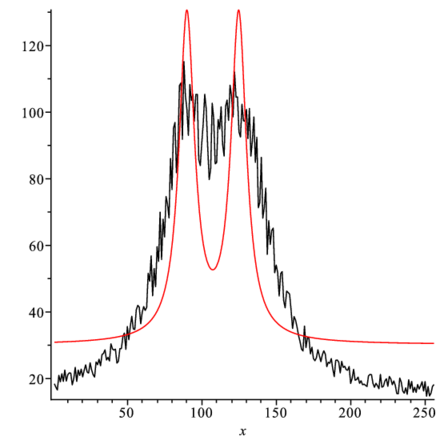 |
何回か繰り返せば,データ点に近づいてくるはず.
Keyword(s):
References:[NumMaple] [NumMapleTOC] [SideMenu]